domingo, 30 de noviembre de 2008
martes, 18 de noviembre de 2008
Valor esperado de una variable aleatoria discreta
La funcion de probabilidad de X puede interpretarse como la proporcion de ensayos en los que
X = x. En consecuencia, en realidad no es necesario realizar el experimento muchas veces con la finalidad de determinar el valor medio de X. La media de X puede calcularsecomo el promedio ponderado de los valores posibles de X, asignando al resultado x un factor de ponderacion
fx(x) = P (X = x).

La media o valor esperado de una variable aleatoria discreta X, denotada por μx o E(X), es
μx = E(X) = Sum. xfx(x)
La media de X puede interpretarse como el centro de la masa del rango de los valores de X. Esto es, si se coloca una masa igual a fx(x) en cada punto x de la recta real, entonces E(X) es el punto donde la recta queda en equilibrio. Por consiguiente, el termino funcion de probabilidad puede interpretarse mediante esta analogia con la mecanica.
Distribucion Hipergeometrica
Por claridad, consideremos el siguiente ejemplo: Tenemos una baraja de cartas españolas (N=40 naipes), de las cuales nos vamos a interesar en el palo de oros (D=10 naipes de un mismo tipo). Supongamos que de esa baraja extraemos n=8 cartas de una vez (sin reemplazamiento) y se nos plantea el problema de calcular la probabilidad de que hayan k=2 oros (exactamente) en esa extracción. La respuesta a este problema es

En lugar de usar como dato D es posible que tengamos la proporción existente, p, entre el número total de oros y el número de cartas de la baraja

de modo que podemos decir que

Este ejemplo sirve para representar el tipo de fenómenos que siguen una ley de distribución hipergeométrica. Diremos en general que una v.a. X sigue una distribución hipergeométrica de parámetros, N, n y p, lo que representamos del modo ![]() , si su función de probabilidad es
, si su función de probabilidad es
![\begin{displaymath}{ \mbox{\fbox{$\displaystyle {{\cal P}}[X=k] = \frac{{ \left... ...box{ \ \ si \ }\max\{0,n-Nq\} \leq k \leq \min\{n,NP\} $ } } } \end{displaymath}](http://www.bioestadistica.uma.es/libro/img982.gif)
Observación
Cuando el tamaño de la población (N) es muy grande, la ley hipergeométrica tiende a aproximarse a la binomial:El valor esperado de la hipergeométrica es el mismo que el de la binomial,
sin embargo su varianza
no es exactamente la de la binomial, pues está corregida por un factor, ![]() , que tiende a 1 cuando
, que tiende a 1 cuando ![]() . A este factor se le denomina factor de corrección para población finita.
. A este factor se le denomina factor de corrección para población finita.
Distribucion Binomial
Un experimento aleatorio que consiste de n ensayos repetidos tales que
(1) Los ensayos son independientes
(2) Cada ensayo tiene solo dos resultados posibles, denominados "exito" y "fracaso", y
(3) La probabilidad de exito en cada ensayo, denotada por p, permanece constante
recibe el nombre de experimento binomial.
La variable aleatoria X que es igual al numero de ensayos donde el resultado es un exito, tiene una distribucion binomial con parametros p y n = 1, 2, ....
La funcion de probabilidad de X es
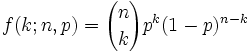
(en terminos de k)
la distribucion se conoce como "bi - nomial".
Ejemplo:


Ensayos de Bernoulli
Ensayo de Bernoulli
1) Los ensayos son independientes
2) Cada ensayo tiene solo dos resultados posibles denominados ¨exito¨ o ¨fracaso¨.
3) La probabilidad de exito de cada ensayo, denotada por P, permanece constante.
Ejemplo:
La probabilidad de recibir de manera erronea un bit transmitido por un canal digital es 0.1 ademas supongase que los ensayos de transmision son independientes.
Sea la variable aleatoria X = al numero de bits recibidos con error en los proximos cuatro que seran transmitidos, describe el espacio muestral de este experimento e indica el valor de x para cada resultado.
P {Recibir de manera erronea un bit} = 0.1
X = {Numero de bits con error en los proximos 4 que sean transmitidos}
P( X = x)
Combinaciones con != Factorial
P(e) = 0.1
P(c) = 0.9 n = 4
P(X=0) = 1 (0.656)
P(X=1) = 4 (0.0729) = 0.2916
P(X=2) = 6 (0.0081) = 0.0486
P(X=3) = 4 (0.0009) = 0.0036
P(X=4) = 1 (0.0001)
Formula: (n/x) = n!/x!(n-x)! o en terminos de m :

Distribuciones de probabilidad discretas
A menudo el interes recae en la probabilidad de que una variable aleatoria tome un valor particular.
En el ejemplo de la tabla anterior, el interes puede centrarse en la probabilidad de que ambas caracteristicas sean aprobadas, esto es, en la probabilidad de que X = 2. El conjunto de todos los resultados para los que {X=2} es un evento formado por un solo resultado (aprobado, aprobado). Por consiguiente, la probabilidad del evento {X=2} es 0.64. Esta conclusion puede escribirse como P(X=2) = 0.64.
De manera similar, el conjunto de todos los resultados para los que {X=1} es un evento compuesto por los resultados (aprobado, inaceptable) e (inaceptable, aprobado).
Para el espacio muestral discreto de este ejemplo, la probabilidad de un evento es la suma de las probabilidades de los resultados contenidos en el evento,
P(X=1) = 0.16 + 0.16 = 0.32
Asimismo,
P(X=0) = 0.04
La tabla siguiente presenta un resumen de los valores posibles de la variable aleatoria X del ejemplo anterior, junto con la probabilidad de cada valor (donde los valores {0, 1, 2} son los valores posibles de X). Dado que X debe tomar uno de estos valores, la suma de todas las probabilidades es uno.

Notese que en estos ejemplos la variable aleatoria esta claramente definida. A menudo este es un paso inicial importante en el proceso de determinar una probabilidad.
El evento que esta formado por todos los resultados para los que X = x se denota como {X = x}, y la probabilidad de este evento como P (X = x).
La distribucion de probabilidad o distribucion de una variable aleatoria X es una descripcion del conjunto de valores posibles de X (rango de X), junto con la probabilidad asociada con cada uno de estos valores. A menudo la distribucion de probabilidad de una variable aleatoria es el resumen mas util de un experimento aleatorio. La distribucion de probabilidad de una variable aleatoria pude darse de muchas maneras. Para una variable aleatoria que puede tomar un numero pequeño de valores, lo mas simple es proceder como en el ejemplo anterior, y listar los valores posibles junto con las probabilidades respectivas. En otros casos, es conveniente expresar en terminos de una formula la probabilidad de que la variable aleatoria X tome un valor x.
Sean p: unamuestra donde esta presente la molecula rara, y a: una muestra donde la molecula esta ausente. El espacio muestral de este experimento es infinito, y puede ser representado por todas las secuencias posibles que comienzan con una cadena de "a" y terminan con p. Esto es:
S = {p, ap, aap, aaap, aaaap, aaaaap, y asi sucesivamente}
Considerense unos cuantos casos especiales. Se tiene que P (X = 1) = P (p) = 0.01 . Por otro lado, si se emplea la hipotesis de independencia,
P (X = 2) = P (ap) = 0.99 (0.01) = 0.0099
Una formula general es
P (X = x) = P (aa...ap) = 0.99 (elevado a la x - 1), para x = 1, 2, 3, ....
La descripcion de probabilidades asociadas con X en terminos de esta formula es el metodo mas sencillo para describir la ditribucion de X en este ejemplo.
---------------------------------------------------------------------------------------------
Funcion de Probabilidad
En el ejemplo anterior la distribucion de X esta descrita por una formula que expresa la probabilidad como una funcion de x. Esto es, la distribucion de X esta especificada por la funcion fx(x) = P (X = x). El subindice de fx(x) denota la variable aleatoria de interes. El subindice se omitira cuando no exista ninguna confusion sobre la probabilidad del resultado. Dado que fx(x) esta definida como una probabilidad, fx(x) es una funcion que va del conjunto de valores posibles de la variable aleatoria al intervalo [0, 1].
Para una variable aleatoria X, fx(x) satisface las propiedades siguientes:
(1) fx(x) = P (X = x)
(2) fx(x) ≥ 0 para toda x
(3) ∑ fx(x) = 1

Funciones de Distribucion Acumulada
Supongase que en el ejemplo anterior el interes recae en la probabilidad de encontrar una molecula rara en tres muestras o menos. Esta pregunta puede expresarse como P (X ≤ 3).
El evento en que {X ≤ 3} es la union de los eventos {X = 1}, {X = 2}, {X = 3}. Al utilizar la notacion del ejemplo, el evento en que {X = 1} esta formado por un solo resultado p, el evento en que {X = 2} esta formado solo por el resultado ap, y el evento en el que {X = 3} por el resultado aap. Es claro que estos eventos son mutuamente excluyentes.
Por consiguiente,
P (X ≤ 3) = P (X = 1) + P (X = 2) + P (X = 3)
--------- = 0.01 + 0.99 (0.01) + 0.99²(0.01)
--------- = 0.0297
Para este ejemplo, existe una formula general,
P (X ≤ x) = 1 - 0.99ª
El ejemplo anterior ilustra el hecho de que en ocaciones es util expresar probabilidades acumuladas, tales como P(X ≤ x), en terminos de una formula. Por otra parte, el mismo ejemplo muestra que una formula para probabilidades acumuladas puede emplearse para encontrar la funcion de probabilidad de una variable aleatoria. En consecuencia, el uso de probabilidades acumuladas es una alternativa para describir la distribucion de probabilidad de una variable aleatoria. Una funcion que proporciona probabilidades acumuladas tiene un gran valor.
E n general, para cualquier variable aleatoria discreta con valores posibles x1, x2, ...., xn, los eventos {X = x1}, {X = x2},....{X = xn} son mutuamente excluyentes. Por consiguiente,
P(X ≤ x) = ∑ fx(xi).
La funcion de distribucion acumulada de una variable aleatoria discreta X, denotada por Fx(x), es
Fx(x) = P(X ≤ x) = ∑ f(xi)
Para una variable aleatoria discreta X, Fx(x) satisface las propiedades siguientes.
(1) Fx(x) = P(X ≤ x) = ∑ fx(xi)
(2) 0 ≤ Fx(x) ≤ 1
(3) Si x ≤ y, entonces Fx(x) ≤ Fx(y)

UNIDAD III - Funciones de distribución de probabilidad
Discreta ---- { X } - Variable aleatoria discreta (se puede contar).
Continua ----{ X } - Variable aleatoria continua (se puede medir) - tiempo, peso, estatura, etc.
Con frecuencia el interes recae en resumir con un numero el resultado de un experimento aleatorio. En muchos de los ejemplos de experimentos aleatorios considerados hasta el momento, el espacio muestral solo es una descripcion de los posibles resultados. En algunos casos las descripciones de los resultados son suficientes, pero en otros es util asociar un numero con cada resultado del espacio muestral. Ya que el resultado de un experimento no se conoce con anticipacion, sucede lo mismo con el valor de la variable. Por esta razon, la variable que asocia un numero con el resultado de un experimento aleatorio se conoce como variable aleatoria.
Una variable aleatoria es una funcion que asigna un numero real a cada resultado en el espacio muestral de un experimento aleatorio.
Las variables aleatorias se denotan con una letra mayuscula, tal como X, y con una letra minuscula, como x, el valor posible de X. El conjunto de los posibles valores de la variable aleatoria X recibe el nombre de rango de X.
Ejemplo:
Se evalua un nuevo proceso para la fabricacion de partes moldeadas en plastico en terminos de la coloracion y reduccion del tamaño. Una de las primeras corridas del proceso proporciona la informacion para el espacio muestral y las probabilidades que aparecen en la tabla.
Supongase que el interes recae en resumir los resultados de este experimento aleatorio con el numero de caracteristicas (de coloracion y reduccion del tamaño) que son aprobadas.
Por lo cual, se define una variable aleatoria, X, para ser igual al numero de caracteristicas aprobadas.
La cuarta columna de la tabla contiene los valores de X asignados a cada resultado del experimento. Por ejemplo, al resultado (aprobado, aprobado) se le asigna x=2.

Ejemplo 2:
El sistema de comunicacion por voz de una empresa tiene 48 lineas externas. En un determinado momento, se observa el sistema y algunas lineas estan ocupadas. Sea X la variable aleatoria que denota el numero de lineas en uso. Entonces X puede tomar cualquier valor entero de cero a 48.
X = {0, 1, 2, 3, 4, 5.....,48}
