



Por claridad, consideremos el siguiente ejemplo: Tenemos una baraja de cartas españolas (N=40 naipes), de las cuales nos vamos a interesar en el palo de oros (D=10 naipes de un mismo tipo). Supongamos que de esa baraja extraemos n=8 cartas de una vez (sin reemplazamiento) y se nos plantea el problema de calcular la probabilidad de que hayan k=2 oros (exactamente) en esa extracción. La respuesta a este problema es

En lugar de usar como dato D es posible que tengamos la proporción existente, p, entre el número total de oros y el número de cartas de la baraja

de modo que podemos decir que

Este ejemplo sirve para representar el tipo de fenómenos que siguen una ley de distribución hipergeométrica. Diremos en general que una v.a. X sigue una distribución hipergeométrica de parámetros, N, n y p, lo que representamos del modo ![]() , si su función de probabilidad es
, si su función de probabilidad es
![\begin{displaymath}{ \mbox{\fbox{$\displaystyle {{\cal P}}[X=k] = \frac{{ \left... ...box{ \ \ si \ }\max\{0,n-Nq\} \leq k \leq \min\{n,NP\} $ } } } \end{displaymath}](http://www.bioestadistica.uma.es/libro/img982.gif)
El valor esperado de la hipergeométrica es el mismo que el de la binomial,
sin embargo su varianza
no es exactamente la de la binomial, pues está corregida por un factor, ![]() , que tiende a 1 cuando
, que tiende a 1 cuando ![]() . A este factor se le denomina factor de corrección para población finita.
. A este factor se le denomina factor de corrección para población finita.
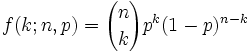




Notese que en estos ejemplos la variable aleatoria esta claramente definida. A menudo este es un paso inicial importante en el proceso de determinar una probabilidad.
El evento que esta formado por todos los resultados para los que X = x se denota como {X = x}, y la probabilidad de este evento como P (X = x).
La distribucion de probabilidad o distribucion de una variable aleatoria X es una descripcion del conjunto de valores posibles de X (rango de X), junto con la probabilidad asociada con cada uno de estos valores. A menudo la distribucion de probabilidad de una variable aleatoria es el resumen mas util de un experimento aleatorio. La distribucion de probabilidad de una variable aleatoria pude darse de muchas maneras. Para una variable aleatoria que puede tomar un numero pequeño de valores, lo mas simple es proceder como en el ejemplo anterior, y listar los valores posibles junto con las probabilidades respectivas. En otros casos, es conveniente expresar en terminos de una formula la probabilidad de que la variable aleatoria X tome un valor x.


Discreta ---- { X } - Variable aleatoria discreta (se puede contar).
Continua ----{ X } - Variable aleatoria continua (se puede medir) - tiempo, peso, estatura, etc.

Ejemplo 2:
El sistema de comunicacion por voz de una empresa tiene 48 lineas externas. En un determinado momento, se observa el sistema y algunas lineas estan ocupadas. Sea X la variable aleatoria que denota el numero de lineas en uso. Entonces X puede tomar cualquier valor entero de cero a 48.
X = {0, 1, 2, 3, 4, 5.....,48}
Probabilidad mediante Conjuntos


a) ¿Como interpretas A U B Y A ∩ B ?
A U B = {112 + 68 + 246} = 426
A ∩ B = {246}
b) Calcula la probabilidad de cada evento?
P (A) = 112 + 246 / 940 = 358 / 940 = 0.38
P (B) = 68 + 246 / 940 = 314 / 940 = 0.334
P (A U B) = 426 /940 = 0.4531
P (A ∩ B ) = 246 / 940 = 0.2617
2)
Despues de tener entrevistas en dos compañias donde quiere trabajar, el evalua la probabilidad que tiene de obtener un empleo en la compañia A como 0.8 y la probabilidad de tenerla en la compañia B como 0.6 . Si por otro lado, considera que la probabilidad de que reciba ofertas de ambas compañias es de 0.5, ¿ Cual es la probabilidad de que obtenga al menos una oferta de esas dos compañias?
A = compañia 1





Si ![]() son mutuamente excluyentes y exhaustivos, es decir, cubren todo el espacio muestral y por lo tanto
son mutuamente excluyentes y exhaustivos, es decir, cubren todo el espacio muestral y por lo tanto ![]() , decimos que
, decimos que ![]() es una partición de
es una partición de ![]() en
en ![]() subconjuntos. Cuando
subconjuntos. Cuando ![]() es una partición se cumple que
es una partición se cumple que ![]() .
.
Se define probabilidad condicional ![]() como la probabilidad de obtener el resultado
como la probabilidad de obtener el resultado ![]() dado que también se obtiene
dado que también se obtiene ![]() :
:
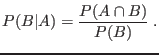
Si E es un evento cualquiera:
P (E´) = 1 - P(E)Tres o mas eventos:
En general, si A y B son dos eventos , se define la probabilidad condicionada del eveto A sobre el B como la probabilidad de que ocurra A habiendo sucedido antes B:
Si A y B son eventos independientes entonces:
Sea A1, A2, ...,An un sistema completo de sucesos tales que la probabilidad de cada uno de ellos es distinta de cero, y sea B un suceso cualquier del que se conocen las probabilidades condicionales P(B/Ai), entonces la probabilidad del suceso B viene dada por la expresión:


Teorema de Bayes:
Sea A1, A2, ...,An un sistema completo de sucesos, tales que la probabilidad de cada uno de ellos es distinta de cero, y sea B un suceso cualquier del que se conocen las probabilidades condicionales P(B/Ai). entonces la probabilidad P(Ai/B) viene dada por la expresión:
![]()
P (B) = P (B/A1) . P (A1) + P (B/A2) . P (A2)+...+ P (B/An) . P (An)
o bien:

El teorema de Bayes parte de una situación en la que es posible conocer las probabilidades de que ocurran una serie de sucesos Ai.
A esta se añade un suceso B cuya ocurrencia proporciona cierta información, porque las probabilidades de ocurrencia de B son distintas según el suceso Ai que haya ocurrido.
Conociendo que ha ocurrido el suceso B, la fórmula del teorema de Bayes nos indica como modifica esta información las probabilidades de los sucesos Ai.



